Impact matters. If a critical Flight Information Service is not available at 9:30 for one minute, this is something different than if exactly the same happens one month later at 9:30, when coincidentally nobody is using the Service. In both cases the SLA might be met (e.g. allowing not less than 99.99% service availability 7×24) and everything looks ‘green’, but in fact the real user impact and finally business impact ($$$) is completely different. This gap between the IT Service View and Business perception needs to be closed. The traditional SLA concept, based on Service Availability, is too technocratic and needs more business perspective. Let’s have a deeper look at this.
Service Level Management is a wonderful thing. It negotiates and agrees the required levels of service quality with your customers, monitors the actual service level achievement and initiates appropriate improvement actions or target adjustments if the agreed targets were not met. A self-regulating, self-fulfilling, never ending circle, striving for continuos improvement. It leads to clear, measurable service delivery and unambiguous expectations between you as a Service Provider and your customer.
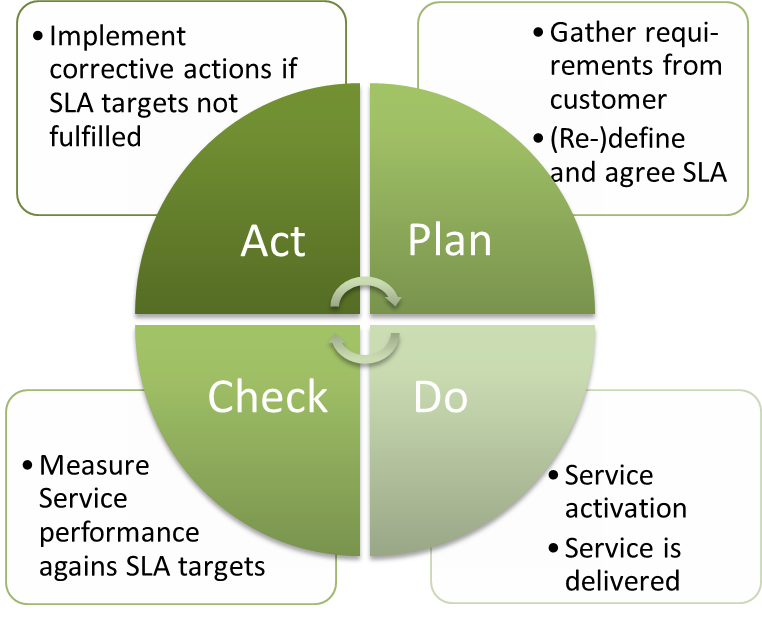
At the times when I was a Service Manager I always hated when my customers just expressed out of the blue ‘I am not happy with your application service xy, e.g. I have the feeling it is too slow’. With Service Level Management it was easy to bring the whole discussion to a new, objective level: Is the actual service quality really worse than agreed? If not (so it’s maybe an expectation or perception thing) – no problem – I can offer you better quality, but it’s gonna cost you more (see also my blog on expectation management for that). If the quality was indeed worse than agreed, the challenge was always to be proactive enough to show the customer that a Service Improvement Plan is already in place to improve things and reach agreed goals. As a tip, this is an excellent way to surprise you customers and to turn something negative (SLA breach) into something positive. Finally Service Level Management is an excellent instrument for establishing a customer relationship: “Let’s sit together each month for a Service Review meeting and discuss our Service performance”. Just as a side node (because there is often confusion about that): SLM is very much concerned with Service warranty (as the whole ITIL is): performance, availability, continuity and security aspects of a service, looking at it in a proactive (Service Design, Transition) and reactive way (Service Operations):

‘How good’ should the service do, how good is it actually performing and how can we improve it cost-efficiently? This is a different question than ‘Is the Service doing the right thing’ (Utility), a question that is rather tackled by Service Portfolio-, Service-Catalogue Management, and most important Requirements Engineering & Solution Design.
Besides all the sunny sides of SLM I mentioned above, there are also some major risks when focusing too much on Service Level Management, especially in outsourced environments: There are Critical Success Factors in Service Management, which cannot be measured and put into an SLA (e.g. friendliness of Service Desk agents) or measurable KPI’s get forgotten, so providers end up just ‘hunting their KPI’s’ and forget what it is all about: Service Mentality (see also my other blog ‘SLA fulfilled – customer unhappy’ for that).
Now having given you a crash-course in SLM and having brought it into a broader context, let’s go to the original topic ‘impact matters’ and first asking the question, what actually should be put into an SLA. In practice, availability is for sure THE service level that customers are interested in. The Business wants to work and if IT Services are not available, this is bad. Depending on the service criticality, which is usually determined by the criticality of the supported business service, the desired level of service is agreed with the customer. If the Business Processes supported by the Flight Information Service are more critical than the Business Processes supported by e-Mail, then the Flight Information Services needs higher availability design. Higher availability means higher cost. Looking at it from a Risk Management perspective it is also a way to get business risks (expressed by probability x impact) under control. The agreed service availability has a direct impact on how the service solution is built (the so-called design for availability & recovery). The problem with all that is that availability targets are built on expectation and probability, but it doesn’t tell you anything about when the Unavailability actually happens and what it means to the business ($$$) in the very specific situation the business is in. Let’s have a look at this logic:
- An IT Service is not available
- This has a negative impact on the users and business processes
- This might have a direct negative impact on the return on investment (ROI) or reputation (VOI) of the company
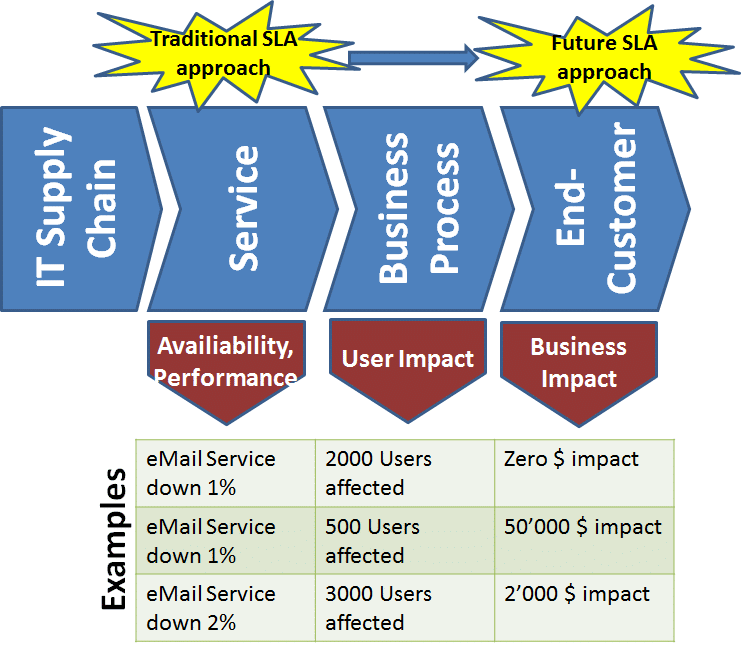
Again, classical Service Level Management is only focusing on the first one. But at the end of the day the customers want to have the third one under control. Let’s make two negative examples, both with same negative SLA breach and penalty, but different financial impact to the company:
- In June, overall e-Mail Service availability was only 99% percent. A malus penalty of $10’000 was paid by the provider due to the SLA breach, as defined in the SLA. User impact was significant, 2000 Users reported to the Service Desk during the outage, but no real financial damage to the company has been proven.
- In July, the e-Mail Service availability was again 99% and the $10’000 penalty was paid. User impact was moderate (holiday season), 500 Users reported to the Service Desk, however it turned out that a couple of Sales Persons were unable to close their deals and lost business. There was a financial damage of $50’000 due to the eMail Outage.
You see, both cases are same from SLA-perspective, but from business perspective the first one was meaningless, the second one not. From a risk insurance perspective, the penalty for the first case should have been $0, for the second $50’000.
For me this has the following consequences to the SLM approach:
- Do not only measure the service by its warranty aspects (e.g. availability) but measure the real financial impact to the business if targets are not met
- The same applies when defining Service Level Targets, try to make the link to business impact, and not only looking at the Service itself
This sound easier than it is, because first of all the provider has only the IT Service under control, therefore only wants to be liable for this. Secondly the financial impact is always something you identify restropectly, it is therefore key how the Service provider reacts to an outage or performance decrease with potential negative business impact. This brings us to the topic of Incident Management, the process which actually handles outages to restore service operation as quick as possible. Incident Handling always needs to be part of an SLA. This is per se nothing new, but you have to do it right:
- Focus on Major Incidents. These are the Incidents that ‘hurt’ and where there is most probably a real link between Service Unavailability, User Impact and negative financial Impact
- Make sure you exactly measure each Major Incidents and understand each time the negative business impact
- As a customer, try to agree in the SLA on the maximum allowed business impact (financially). Penalties should be based on business impact and this will force the provider to put the right priorities, when an incident happens.
To sum up: A good SLA should achieve the right balance between proactive and reactive measures. Availability targets make sure, the Service and underlying systems have the right availability design and generally meet availability expectations, reactive incident targets based on Business impact makes sure the right priorities are set when the incident actually happens.