
Datenqualität, ein immer stetig vorhandenes Thema. In der Vergangenheit wurde Bücher und xig Artikel darüber geschrieben. Mangelnde Datenqualität kann hohe Kosten verursachen, verfälscht Analyseergebnisse und darauf basierend können gar falsche Entscheide getroffen werden.
Gehen wir kurz 2 – 3 Schritte zurück – was ist eigentlich Datenqualität? Nun – als eine mögliche Definition lesen wir in Wikipedia: „Der Begriff Datenqualität (als Qualitätsmaß für Daten) steht der ‚Informationsqualität‘ sehr nahe. Da die Grundlage für Informationen ‚Daten‘ sind, wirkt sich die ‚Datenqualität‘ auf die Qualität der Informationen aus, die aus den entsprechenden Daten gewonnen werden: Keine „gute“ Information aus schlechten Daten.“
Daten sind für jede Firma wertvoll. Mit deren Verbreitung und vermehrter Nutzung von „Social Network“ wird das Datenvolumen massiv zunehmen. Konkret heisst das, dass sich das private Datenvolumen bis 2018 quasi verdoppeln soll, d.h. ein Zuwachs pro Jahr von 20-25%.
Das neue Schlagwort ist hier „big data“. Jedoch wird es damit auch nicht einfacher, sei es mit der Erfassung von Stamm- und Bewegungsdaten oder ganz am Ende der Prozesskette, mit den unterschiedlichsten Auswertungen.
Untenstehend eine Statistik dazu (Quelle „Statista“):
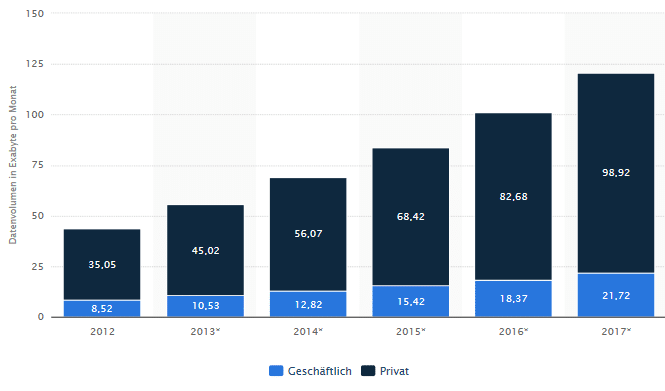
Gehen wir aber zurück zum Thema Datenqualität – dies wird umso wichtiger bei diesem immensen Daten – Wachstum.
Wer kennt dies nicht schon z.B. die Kundendaten in einem CRM, da wechselt eine Person von der Firma A in die Firma B. Plötzlich hat man 2 gleiche Personen im CRM, welche zusammen gebracht werden müssen. Oder eine weibliche Person wird mit „Herr“ angeschrieben – dies kann zu einer Image Einbusse führen.
Wenn ich auf meine Apps auf dem Handy gucke, werde ich regelmässig gefragt, ob mein Standort erhoben werden darf. Konkret bedeutet dies, dass hier Funktionen zur Datenanreicherung, etwa um Geo-Daten oder Telefonnummern angefragt wird. Das erhöht den Wert der Daten. Was für die Firmen einen klaren Mehrwert der Datenanreicherung spricht, dem trete ich privat mit gemischten Gefühlen entgegen. Was passiert mit all den verlangten Zugriffen auf meine Handyfunktionen wie Mikrofon, Kalender, Kontaktdaten etc.? Zugegeben, nur widerwillig stimme ich bei manchen Apps hier ein. Konsequenterweise hiess es für mich, dass ich mich auch schon von Apps verabschiedet habe, d.h. deinstalliert habe.
Was passiert ausserhalb – im Internet während einer Minute? Diese Grafik zeigt die immense durchschnittliche Datengenerierung an während 60 Sekunden an:
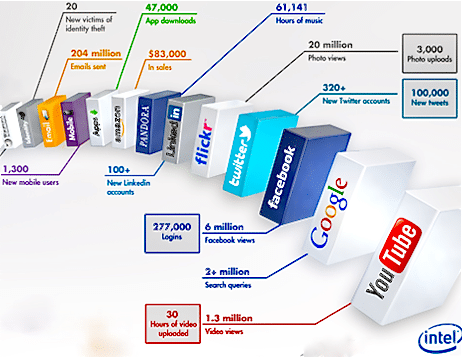
In Anbetracht der immer komplexer werdenden IT Umgebung mit Multisourcing, ja ggf. mit Teilen aus der Cloud, kriegt dieses Thema wieder Bedeutung. Nicht zuletzt muss ich mich in diesem Fall versichern, dass meine Daten nicht irgendwo auf dem Globus abgespeichert werden, sondern muss sicherstellen, dass ich die die gesetzlichen Vorgaben einhalten, „compliant“ bleibe.
Datenqualität – unterschiedliche Sichten
Somit hat Datenqualität verschiedene Aspekte, welche wichtig sind. Diese sind u.a.
- Korrektheit (die Daten müssen mit der Realität übereinstimmen),
- Konsistenz (ein Datensatz darf in sich und zu anderen Datensätzen keine Widersprüche aufweisen),
- Zuverlässigkeit (die Entstehung der Daten muss nachvollziehbar sein),
- Vollständigkeit (ein Datensatz muss alle notwendigen Attribute enthalten),
- Genauigkeit (die Daten müssen in der jeweils geforderten Exaktheit vorliegen (Beispiel: Nachkommastellen),
- Aktualität (alle Datensätze müssen jeweils dem aktuellen Zustand der abgebildeten Realität entsprechen),
- Redundanzfreiheit (innerhalb der Datensätze dürfen keine Dubletten vorkommen),
- Relevanz (der Informationsgehalt von Datensätzen muss den jeweiligen Informationsbedarf erfüllen) und
- Einheitlichkeit (die Informationen eines Datensatzes müssen einheitlich strukturiert sein).
Wie sollen wir jedoch in Zukunft alle diese Aspekte noch bewältigen können. Eine Vielzahl von Tools wird auf dem Markt angeboten. Gartner hat dazu eine Positionierung in ihrem bekannten „Magic Quadrant“ erstellt:
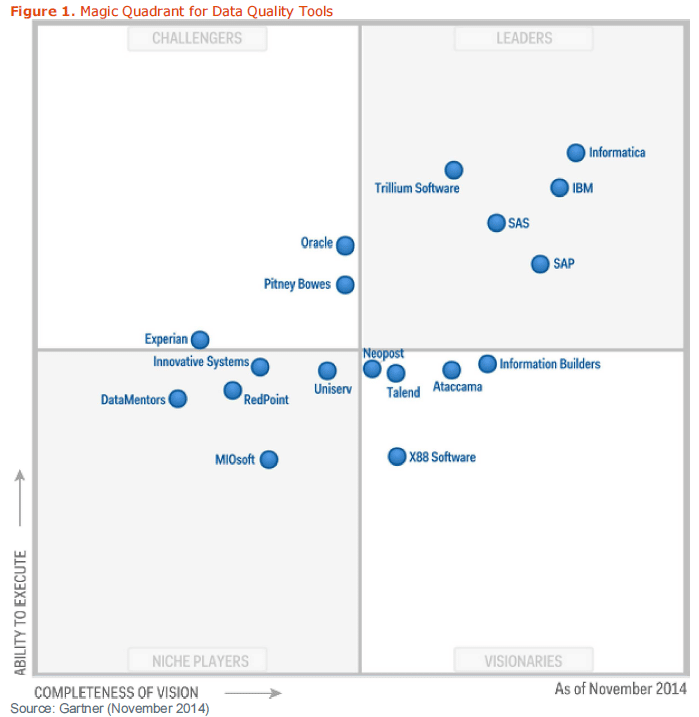
Eine Vielzahl von Tools stehe hier uns zur Verfügung, welche uns helfen, die Datenflut zu strukturieren und nach den gewünschten Sichten zu reporten. Zugegeben, ganz so einfach ist dies alles nicht. Gewisse Firmen zahlen hierfür einen 2-stelligen Millionenbetrag, um ihre zig CMDB zusammenzuführen, d.h. von über 30 CMDB‘s auf eine „handvoll“ relevanter CMDB’s zu konsolidieren und Klarheit betreffend dem Daten-Master/-system zu erhalten. Die Projektdauer ist dementsprechend zwischen 2-3 Jahre mit unterschiedlichen Etappen und Zwischenzielen.
Und was bringt das alles – welchen Nutzen hat man nun davon?
Einerseits gibt es direkten Nutzen, andererseits aber auch indirekten Nutzen bei einer Steigerung der Datenqualität, z.B.:
- Direkter Nutzen: keine Doppelerfassung und Datenkorrekturen, Rückläufer
- Indirekter Nutzen: Fehlentscheidungen, Zeitverlust, Suchdauer, Arbeitsstunden
- Ein wichtiger Bestandteil bei der Datenqualität ist der Verbesserungsprozess. Dieser basiert auf dem bekannten Deming Circle (PDCA – Plan, Do, Check, Act) oder „KVP, kontinuierlicher Verbesserungsprozess“ genannt.
Erfolgsfaktoren für eine Verbesserung der Datenqualität sind u.a.
- Aktive(re) Benutzerführung in den wichtigen Kernapplikationen
- Die wichtigsten Schlüssel-Begriffe einheitlich und unternehmensweit definieren und verwenden
- Automatisieren des Datenflusses
- Integration von Software frühzeitig planen unter den Data-Qualitätsaspekten
Was bringt die Zukunft?
Gewisse Firmen habe in der letzten Jahren vermehrt solch spezifische Stelle geschaffen, sei es eine Rolle „Data Quality Manager“ oder „CDQM Data Architekt“ (Corporate Data Quality Management). Damit schaffen diese in der Organisation die Voraussetzungen, dass das Thema Datenqualität organisatorisch verankert ist und langfristig sowie nachhaltig einen Mehrwert bringt.
Viel wichtiger als die Datenqualität ist die Informationsqualität, die in diesem Beitrag nicht angesprochen wird. Die Informationen sind die Wertschöpfung. Die Informationen bilden die Realität ab. Analogie: Erdöl ist ein wichtiger Rohstoff, die Wertschöpfung entsteht in der Raffinerie (Heizöl, Benzin usw.). Genauso sind die Daten der Rohstoff für die Informationen.
Eine Person X ist ein Datum. Eine Adresse Y ebenfalls. Beide können für sich betrachtet richtig oder falsch sein. Es ist für mich ohne Bedeutung. Ist die Person X ein Kunde von mir, ist das für mich eine schützenswerte Information. Der Kunde X hat seinen Sitz an der Adresse Y. Auch das ist für mich eine wichtige Information. Die Adresse Y ist ein Datum, das korrekt sein muss. Für sich allein betrachtet, ist das Datum Adresse Y für mich wertlos. Erst durch die Verknüpfung der Adresse Y mit dem Kunden X entsteht eine für mich wichtige/wertvolle Information, die es zu schützen gilt.
Fazit: Datenschutz/Datenqualität ist eine Teilmenge des Informationsschutzes/der Informationsqualität. In der Praxis ist das weitgehend verankert. Darum irritiert mich dieser Artikel ein wenig.
Besten Dank für die Ergänzung. Dieser kann ich nur zustimmen.