
Wieso soll man sich für eine neue Methode begeistern, welche alte Weisheiten und hart erarbeitete Prinzipien in einem IT Betriebskonzept über den Haufen werfen? Wenn Änderungen in der Produktion verstärkt und beschleunigt werden, wird doch automatisch auch das Risiko erhöht. Und wenn die Kontrolle über die Produktion den Händen der Entwickler überlassen wird, so wird die Büchse der Pandora geöffnet. Wie kann so ein Zustand einem seriösen IT-Auditor erklärt werden?
Die Operations-Leute haben guten Grund, die Produktion zu schützen und unkontrollierte Änderungen möglichst zu vermeiden. Andererseits wollen die Entwickler dem Druck des Business Rechnung tragen und möglichst schnell neue Funktionalität liefern. Ein klassischer Zielkonflikt, welcher die IT in den letzten Dekaden geprägt hat und der bis heute nie richtig gelöst werden konnte. Ein inhärenter Zielkonflikt sozusagen. Das Business soll wählen zwischen «schnell und hudelig» oder «langsam dafür stabil». Qualität vor Zeit wurde dem Business beschieden, weil ansonsten keine Garantie für was da alles passieren kann, übernommen wurde.
Mit DevOps soll das plötzlich alles anders sein? Setzen sich die Delivery-getriebenen Entwickler bei den Produktionsverantwortlichen einfach so durch? Wird die neue Zukunft so lasch mit Risiken umgehen? Das kann ja nicht ernsthaft gut kommen.
Man muss sich von dieser stereotypischen Sichtweise lösen, will man das Phänomen «DevOps» besser verstehen. Es ist bei weitem nicht so, dass der Entwickler die Produktion in die Knie zwingen will. Auch der Produktionsverantwortliche will die Weiterentwicklung des Business nicht verhindern. Alle wollen im Grunde einen guten Job machen und ihren Beitrag zum Erfolg des Unternehmens beitragen. Das ist bereits eine wichtige Grundeinstellung, wenn gemeinsam an einer neuen Lösung gearbeitet werden soll.
Es braucht auch ein Hinterfragen von bestehenden Denkmustern. Da Veränderungen und Stabilität in aller Regel diametral entgegengesetzt sind, werden Änderung aufgeschoben, um sie dann in grösseren gesammelten “Chargen” als Release in die Produktion zu überführen. Komplexe Systeme reagieren nicht gut auf solche grosse Störungen. Es ist effektiver, die Changes kontinuierlich über die Zeit in kleinen Schritten gesteuert umzusetzen. Daraus ergibt sich die paradoxe Erkenntnis, dass häufigere Wechsel besser für Stabilität sorgt. Wer sich die Zeit nehmen kann, verfolgt doch den spannende Keynote von Adrian Cockcroft, Netflix zum Thema «Velocity and Volume (or Speed wins)».
Eine andere Sichtweise ist auch die Wahrung der gläsernen Produktion. Wenn die Volatilität der Änderungen künstlich unterdrückt wird, dann neigt die Produktion dazu, eher anfällig auf Änderungen zu reagieren. Risiken sind kaum sichtbar, weil permanent versucht wird, «jeglichen» Schaden von der Produktion fernzuhalten. Wenn dann doch etwas passiert, so tendiert es, kritisch für das Business zu werden, weil der Fehler wie eine Stecknadel im Heuhaufen des grossen Releases gesucht werden muss. Die Risiken, einzuschätzen, ob es etwas schiefgehen kann, ist im Grunde gar nicht wirklich möglich. Wenn es schiefgeht, ist der Schaden bei komplexen, fragilen Systemen entsprechend gross. Es ist wie beim richtigen Leben. Wer in steriler Umgebung aufwächst, lernt sich nicht im «dreckigen» Alltag zu behaupten.
Daher reicht es nicht, dass die Produktion zu verhindern versucht, dass etwas passiert. Vielmehr muss der Entwickler seine Software so bauen, dass diese robust ist. Die Qualität muss in der Antifragilität der entwickelten Lösung sein. Dies bedeutet hierbei nicht einfach nur Robustheit oder Stärke, sondern viel mehr die Eigenschaft auf Fehler im System und auf sich spontan ändernder Randbedingungen in geigneter Weise, eben antifragil, reagieren zu können. Lies hierzu den spannenden Blog von Jez Humble «On Antifragility in Systems and Organizational Architecture».
Wenn letztlich eine geprüfte und automatisierte Deployment-Engine die robuste und antifragil getestete Software in die Produktion einspielt, dann hat auch kein IT-Auditor ein Problem. Die Prüfspur ist nachvollziehbar und der Ablauf vor unkontrollierten Zugriffen geschützt.
Wie entwickelt man sich nun zu einem DevOps-Team?
IT-Organisationen, welche DevOps nicht wirklich verstehen, tendieren dazu, als erstes gleich ein Tool zu beschaffen. Ein Tool ist Problemlöser Nummer eins in der IT – das war es schon immer gewesen.
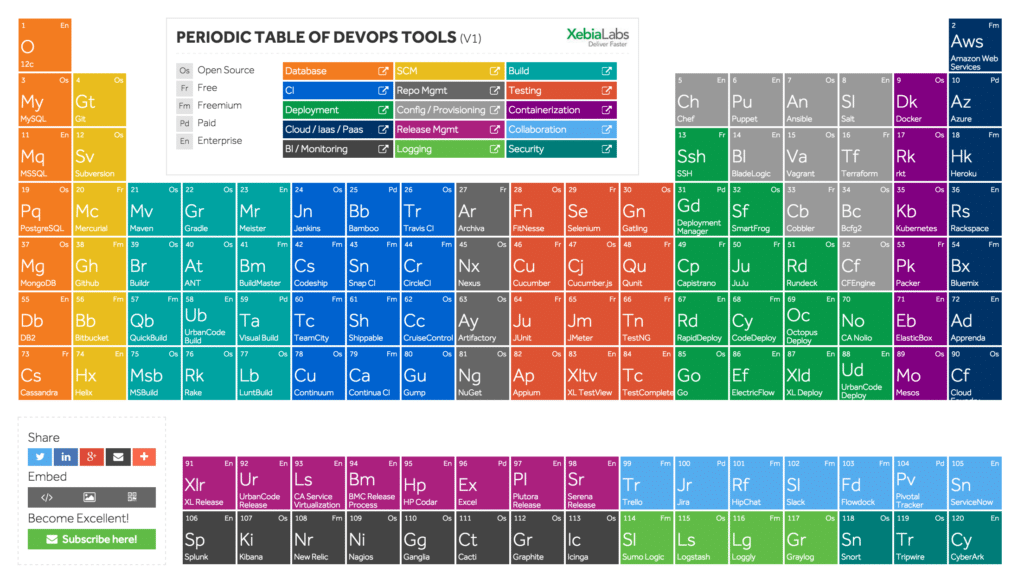
Aber: «A fool with a tool is still a fool». DevOps ist bei weitem nicht bloss eine technische Herausforderung. Vielmehr zielt DevOps auf das Einreissen der Silo-Mauern zwischen unterschiedlich beteiligten Silo-Bereiche ab. Das sind nicht bloss die «Entwicklung» und «Operation». Das schliesst das Requirement-Engineering, die Security, die System-Admins, DBAs, Release Engineers, die Netzwerk-Spezialisten und alle beteiligten externen Supplier gleich mit ein. Jeder muss lernen, über seinen Tellerrand zu schauen. Er muss auch lernen zu verstehen, was es braucht, um innovative Lösungen zu entwickeln und verlässliche Services bereitzustellen. Der Schlüssel zum Erfolg liegt in dem näheren Zusammenrücken und dem gemeinsamen Verständnis des Werteversprechens gegenüber dem Business. Gemeinsam neue Lösungswege zu erproben, mit direkten Feedback-Loops und dem stetigen Drang, die abgestimmten Ziele zu erreichen, bilden den fruchtbaren Boden, auf denen der Flow von Business-Anforderungen bis hin zu verlässlichen IT Services schnell, flexibel und letztlich auch kostenoptimal realisiert werden kann. Und wenn letztlich auch ein gutes Tool seinen Beitrag dazu leistet, dann soll es auch DevOps recht sein.
Diese geforderte, interdisziplinäre Zusammenarbeit stellt sich nicht so einfach ein. Solche Teams müssen sich permanent fordern und ihre Reife über die gemeinsam gemachten Erfahrungen laufend weiterentwickeln. Gut veranschaulichen lässt sich dies anhand des DevOps Maturity Modells von Open Group, im Whitepaper IT4IT Agile Scenario.
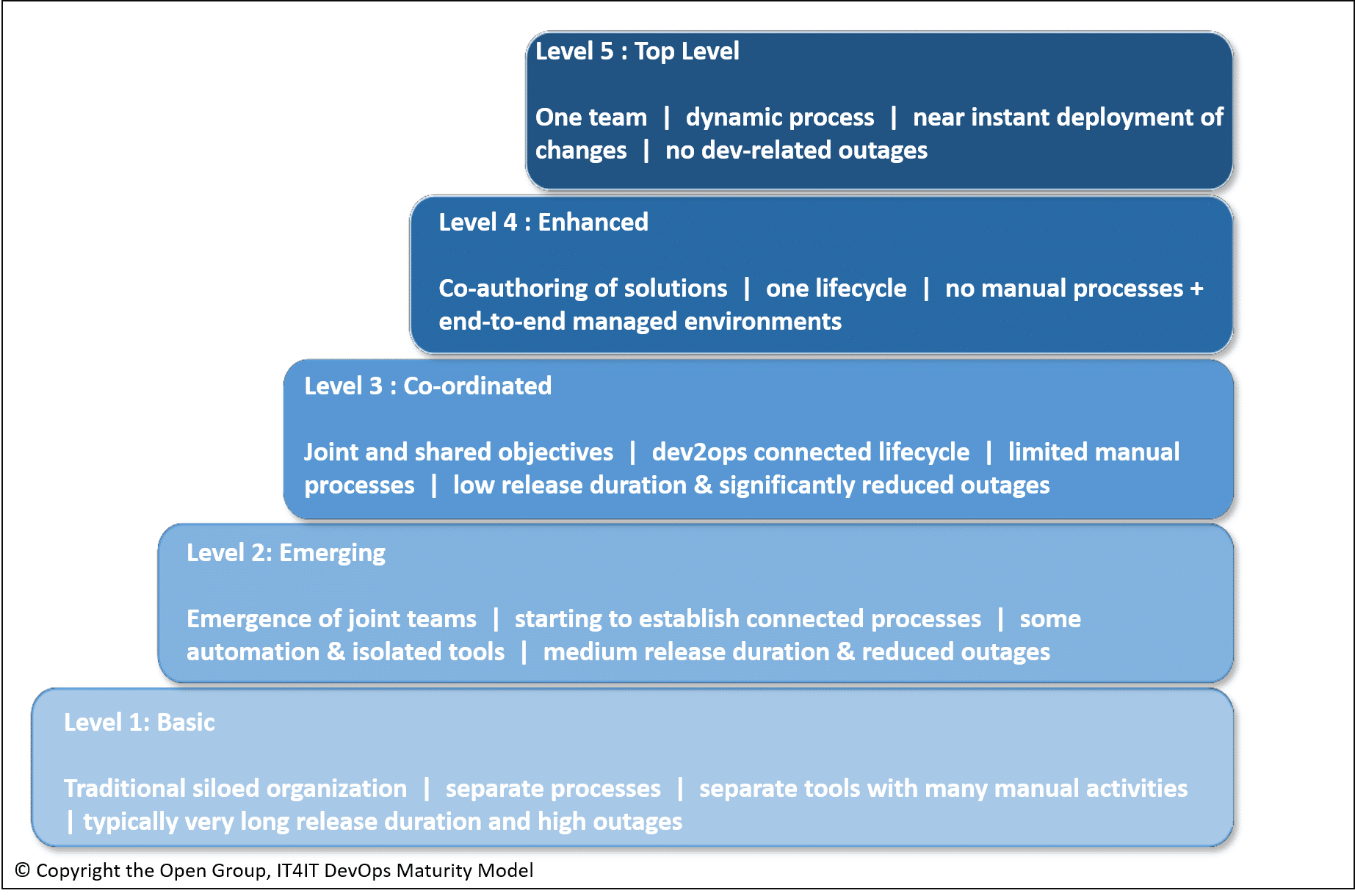
- Auf dem Basic Level 1 ist DevOps bei den Leuten noch nicht wirklich angekommen. Es gibt für alle Funktionen eigene Teams, welche sich nicht wirklich absprechen und auch keine gemeinsamen Begriffe und Referenzen verwenden. Alle Teams konzentrieren sich auf ihre eigenen Ziele. Jeder ist nur für seine unmittelbare Umgebung verantwortlich – und niemand für das gesamte Ergebnis.Prozesse sind auch eher ad hoc und reaktiv, wenn überhaupt. Es gibt keine gemeinsamen Prozessziele und keine Schnittstellenkoordination. Auch Toolseitig sind eher wenige Werkzeuge vorhanden. In der Regel werden manuelle Schritte ausgeführt. Sowohl beim Release Bau, Testen und Rollout.
- Beim Emerging Level 2 sind erste Verbesserungen sichtbar. Zwar herrscht immer noch eine Silomentalität vor und niemand hat eine End-to-End Verantwortlichkeit. Aber es gibt bereits Berührungspunkte zwischen Entwicklern, welche sich für Produktionsanliegen engagieren und Betriebsleute, welche die Entwickler aktiv unterstützen.Die Prozesse sind im Level 2 besser gesteuert – aber dies auch nur in ganz spezifischen Bereichen, wie beispielsweise bei Benutzerabnahmetests. Technisch wird bereits vermehrt mit automatisierten Skripts gearbeitet – dies aber eher bei den Entwicklern.
- Beim Coordinated Level 3 sind die Teams zwar immer noch eher in Silos, haben aber spezifische Funktionen wie beispielsweise Architekten, welche den Sope von der Entwicklung bis zur Produktion erweitern. Die Operations-Leute werden stärker in die Design- und Build-Phase einbezogen.Die Prozesse sind zwar immer noch isoliert, decken aber mittlerweile den gesamten Solution Lifecycle ab. Technisch werden die Entwicklungsumgebungen automatisch bereitgestellt. Nur noch applikationsbezogene Installationen erfolgen manuell.
- Beim Enhanced Level 4 bestehen gemeinsame Teams über den gesamten Solution Lifecycle. Der Lead Architekt ist Owner der gesamten Lösung inklusive den funktionalen und Nicht-Funktionalen Aspekten während dem Design, Build, Test und Betrieb.Die Prozesse sind eher integriert und decken den gesamten Solution Lifecycle ab. Die Abhängigkeiten der Software-Änderungen sind transparent und die Compliance sichergestellt. Technisch ist die gesamte Entwicklungsumgebung, inklusive Server, Betriebssysteme, Middleware und applikationsbezogenen Komponenten automatisiert.
- Der Top Level 5 zeigt ein Team, welches gemeinsam zusammenarbeitet und aktiven Wissensaustausch betreibt. Die Prozesse decken alle Bereiche von der Strategie, über den Design, Build, Test und Betrieb integriert ab. Technisch sind alle Abläufe automatisiert und keine manuellen Schritte mehr notwendig.
Damit DevOps erfolgreich eingeführt werden kann, muss auch hier eine Business Case Betrachtung gemacht werden. Es geht mehr als um automatisierte Code-Migration. Es braucht ein Verständnis über die notwendigen Veränderungen bei den Menschen, Prozesse und Technologien – ausgehend vom Ist-Zustand zu einem neuen Zielbild. Die Bedeutung des Nutzens von DevOps muss für die Organisation sehr gut verstanden werden, damit die Umsetzung auf einem starken Business Case abgestützt werden kann. Nicht jede Organisation profitiert im gleichen Masse von DevOps.
DevOps kann aber sehr spannend werden, wenn man alte Sichtweisen über Board zu werfen bereit ist: Teams erlernen gemeinsam, schneller und in grösseren Taktraten zu liefern und gleichzeitig sich besser auf das Business auszurichten. Mit DevOps wird der Graben zwischen Entwicklung und Betrieb zugeschüttet. Stabilität und hohe Änderungsdichte müssen kein Widerspruch mehr sein.
Diese neue Sichtweise wird wohl nicht alle «alten» Hasen der IT überzeugen. Aber sie wird sich über die Zeit durchsetzen. Davon bin ich überzeugt.